In August 2024, we launched a dataset collection effort on the swipe.futo.org domain to collect QWERTY English swipes. Users would voluntarily visit the webpage on their mobile phone and be given instructions and information about the dataset. After consenting, they would be given sentences, primarily from Wikipedia, and would be asked to swipe them word-by-word.
In the end, this produced over 1 million swipes. We filtered out a small set of low-quality swipes. In March 2025, we released a dataset of 1 million swipes under the MIT license, and it is available today on HuggingFace.
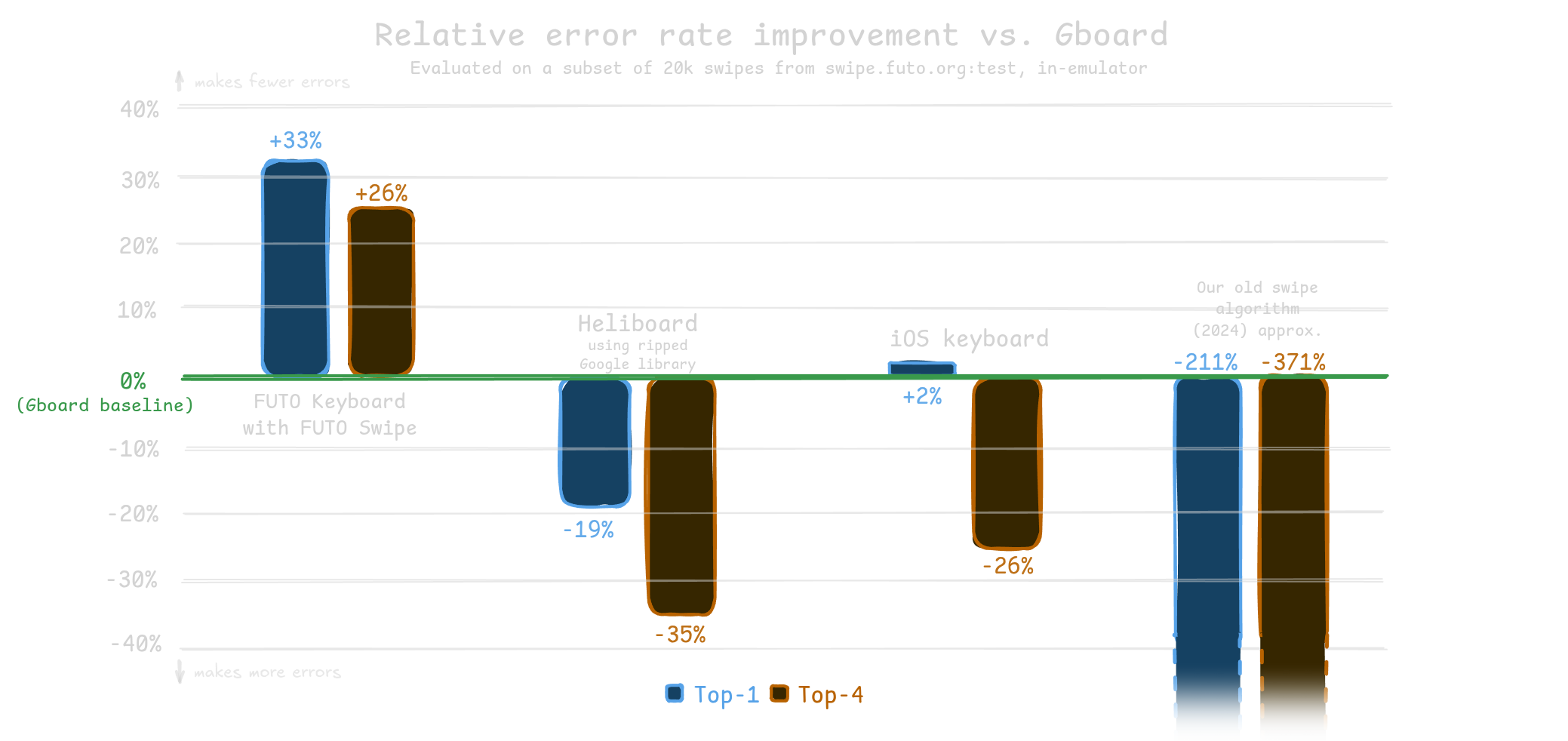
We made heavy use of this data to train our models and to evaluate different swipe typing systems.